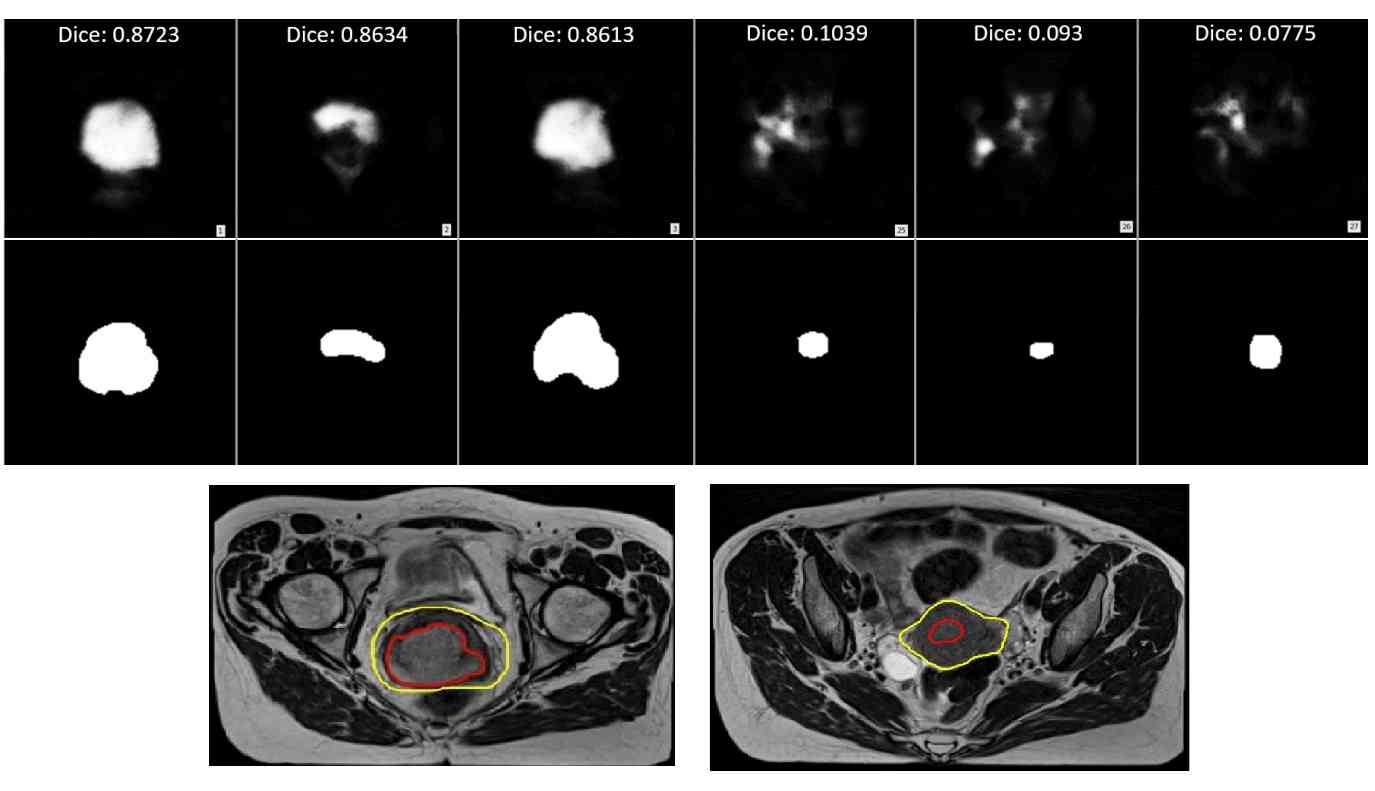
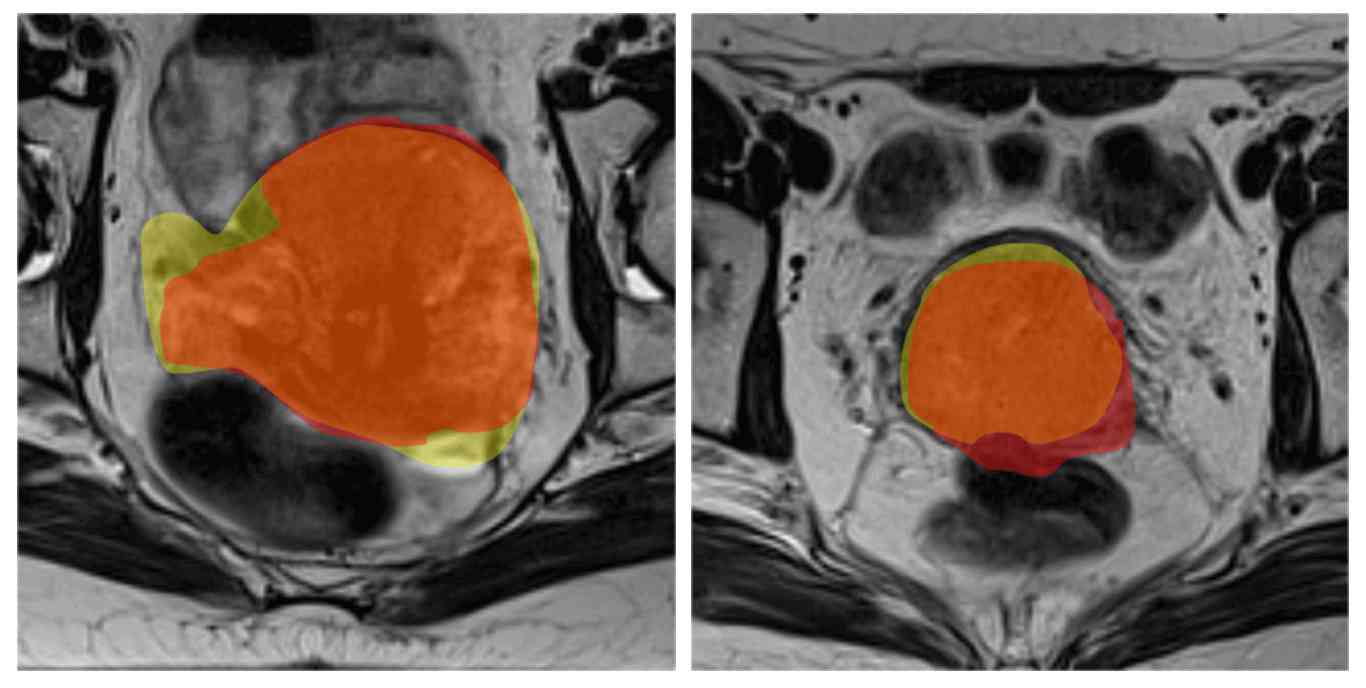
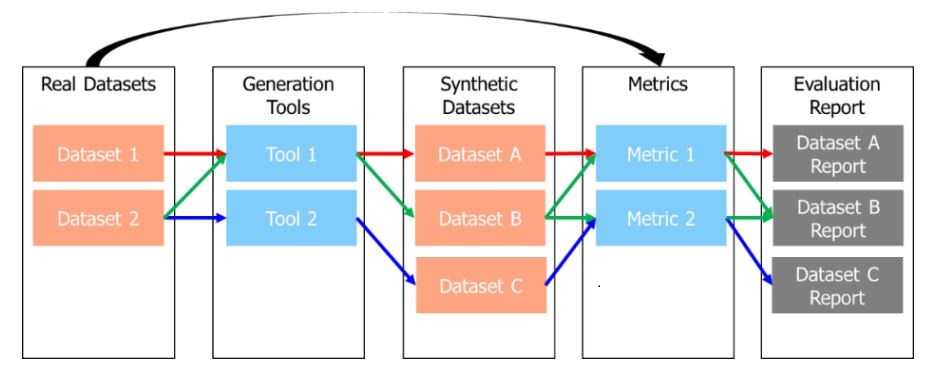
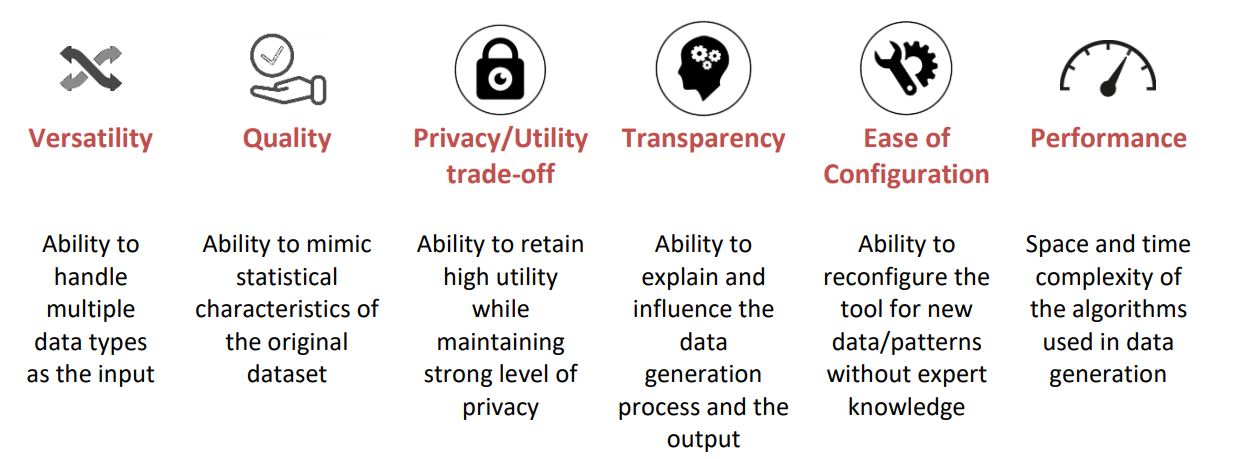
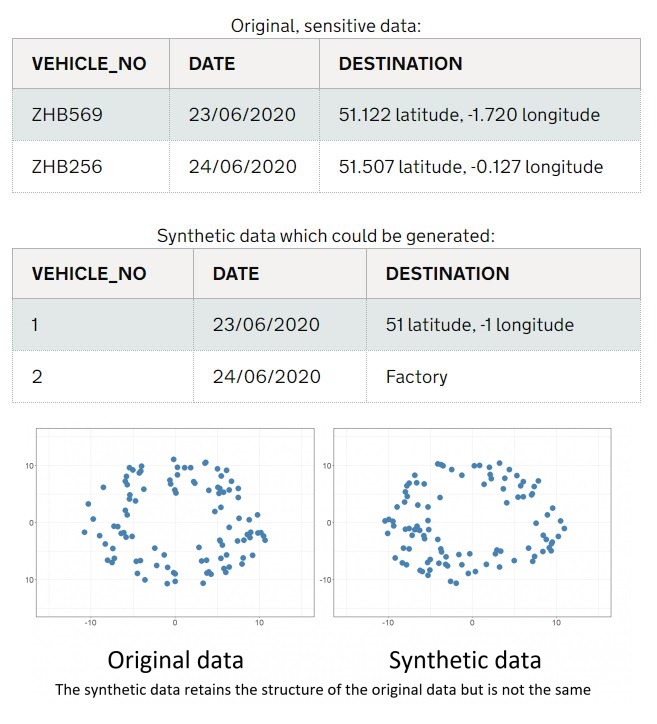
ABOUT ME

Since graduating from the University of Manchester with a degree in Physics, I have worked as a developer on a range of machine learning projects using Python and out of my own personal interest I have also been learning SQL as well as front-end web development. I'm a naturally curious, adaptable person who has worked independently on projects, within teams and, on occassion, assisted with managing projects as well. I am a quick learner and an excellent communicator too, and have written reports and given presentations aimed at people from all sorts of backgrounds and levels, both technical and non-technical.